
ATCA刀片完美搭配Intel® DPDK技术显著提升包转发服务性能
该白皮书以IP转发作为包处理的一个典型示例,说明了如何将凌华科技aTCA-6200A刀片式服务器与Intel® DPDK技术整合为单一平台,提供所需的处理性能,并实现包处理服务性能的提升。首先,我们来比较在没有使用Intel® DPDK做任何优化时,采用原生 Linux(Native Linux) IP转发时aTCA-6200A的第三层转发性能。然后,我们再分析采用Intel® DPDK技术之后所获得的IP转发性能提升的原因。最后,我们将介绍凌华科技基于Intel® DPDK技术的自己的开发工具包,该工具包可以协助用户轻松地开发自己的基于Intel® DPDK的应用。
凌华科技aTCA-6200A
凌华科技aTCA-6200A是一款高集成度的AdvancedTCA处理器刀片,支持2个Intel® Xeon® E5-2648L处理器(Sandy Bridge-EP,32nm),每一个处理器可以最多提供8核20MB的共享缓存。通过使用Intel®超线程技术(Intel® HT技术),每个处理器可以最多支持16个物理线程。除此之外,aTCA-6200A还支持8通道的DDR3-1600 VLP RDIMM内存,每个处理器可以支持最大64GB的系统内存。aTCA-6200A还包含了丰富的网络I/O接口,包含2个兼容PICMG 3.1 option 1/9的10GbE口(XAUI,10GBase-KX4),以及最多6个10/100/1000BASE-T千兆以太网端口,可分别连接至前面板,AdvancedTCA Base接口通道和后走线千兆以太网口。
凌华科技aTCA-6200A处理器刀片主要针对运营商级别的安全和电信应用,同样在网络基础设施中也可作为IMS服务器、媒体网关、包检测服务器、流量管理服务器和WLAN接入点控制器等。
下图1的功能示意图展示了凌华科技aTCA-6200A的详细架构。
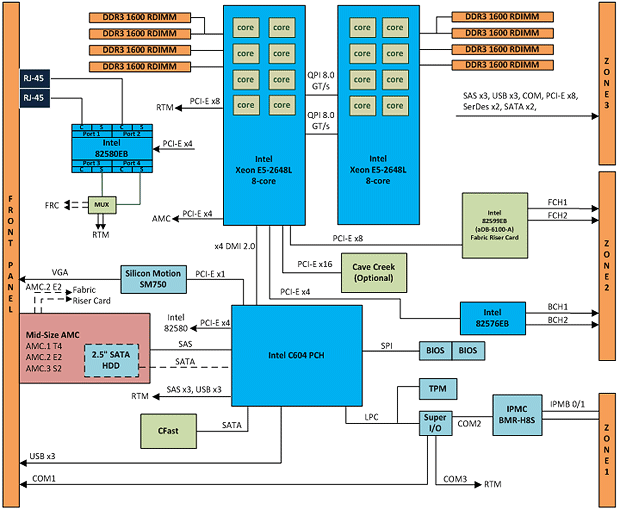
图1:aTCA-6200A功能示意图
Intel® DPDK
Intel® DPDK(Intel® Data Plane Development Kit,Intel® 数据平面开发套件)是一个专为Intel®架构处理器提供的轻量级运行环境。它提供了低功耗和Run-to-Completion(RTC,运行到完成)模式,以此最大限度的提升数据包的处理性能。而且Intel® DPDK还包含了优化的和高效的函数库,为用户提供丰富的选择,例如我们熟知的环境抽象层(EAL,Environment Abstraction Layer),它负责初始化和分配低级资源,同时隐藏来自应用和函数库的环境特性,并且获取低级资源,如内存空间,PCI设备,定时器和控制
环境抽象层(EAL)提供优化的轮询模式驱动(PMD,Poll Mode Driver),内存和缓存管理,定时器,调试和包处理API,其中有些功能也可以由Linux操作系统提供。为使应用层间的相互协作更加便利,环境抽象层(EAL)与标准的GNU C Library(GLIBC)一起,提供集成了更高级别应用的完整API。
下图2为软件层级结构图。
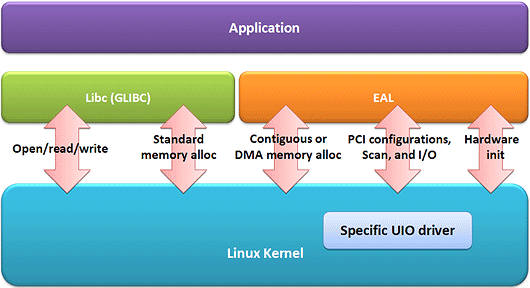
图 2:在Linux应用环境中的EAL和GLIBC
测试拓扑结构
为了测量aTCA-6200A在第三层进行处理和转发IP包的速度,我们使用图3中所示的环境进行测试。
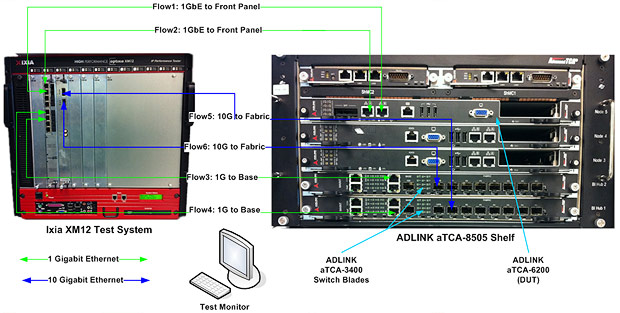
图3: IP转发测试环境
如图3所示,两片凌华科技aTCA-3400交换刀片,通过使用FASTPATH®网络软件,为安装在凌华科技aTCA-8505机箱中的3片处理器刀片上自带的10GbE Fabric和1GbE Base接口通道提供了无阻碍的互连交换,并支持全网(Full-Mesh)拓扑结构。因此,每个aTCA-3400交换刀片可以提供至少一个Fabric和Base接口,用以连接到每个处理器刀片,例如安装在第5槽的aTCA-6200A刀片(被测设备)。
Lxia XM12测试系统,兼容RFC 2544吞吐量基准,通常被用来作为包数据的模拟器,用以发送不同帧大小的IP数据包,并收集最终的统计数据,如每秒帧数吐量。
根据上图所示的测试环境拓扑结构,aTCA-6200A作为处理器刀片,包含了四个千兆以太网口:两个来自前面板(Flow 1和Flow 2),另外两个是通过aTCA-3400 Base交换实现的Base接口(Flow 3和Flow 4)。除了这4个1GbE的接口之外,aTCA-6200A还有2个10GbE的接口通过aTCA-3400交换板连至lxia XM12(Flow 5和Flow 6)。
在这个测试配置中,aTCA-6200A作为被测设备(DUT),负责接收来自lxia测试系统的IPv4数据包,并在第三层处理这些数据包(例如数据包解封装,IPv4报头校验和验证,路由表查找和数据包封装),然后根据路由表查找结果将数据包返回至lxia XM12。所有的六个流向都是双向的:例如,lxia XM12通过1/2/3/4/5/6接口发送帧数据给aTCA-6200A,并分别通过1/2/3/4/5/6接口接收帧数据。
测试方法
为了评估Intel® DPDK如何在凌华科技aTCA-6200A上实现包转发服务的提升,在下面的两个测试案例中我们使用了基于Intel® DPDK的IP包转发应用:
在Native Linux下的性能
在这个测试环境中,aTCA-6200A安装了64位Ubuntu Server 11.10。同目前Linux其他版本一样,IP转发功能默认是禁用的,需启用IP转发功能,同时使用以下命令禁用ufw服务。
| # sudo ufw disable # sysctl net.ipv4.ip_forward net.ipv4.ip_forward = 0 |
同上,将net.ipv4.ip_forward设置为0,当前内核配置下的IP转发功能将被禁用。但是通过以下命令可以立即启用:
| # sysctl -w net.ipv4.ip_forward = 1 or # echo 1 > /proc/sys/net/ipv4/ip_forward |
如果在/etc/sysctl.conf中将net.ipv4.ip_forward设置为1,并重启网络服务,IP转发功能将默认启用,如下所示:
| #echo "net.ipv4.ip_forward = 1">/etc/sysctl.conf # /etc/init.d/network restart |
使用Intel® DPDK后的性能
Intel® DPDK可以在不同的模式下运行,如裸机(Bare Metal),带裸机实时(Bare Metal Run-Time)的Linux和Linux 用户空间(User Space)。在最初的开发阶段,Linux用户空间(User Space)模式是最容易使用的,请参看Intel Data Plane Development Kit - Getting Started Guide for Linux。中的相关描述。下图4描述了Intel® DPDK在Linux用户空间(User Space)模式下的详细功能。
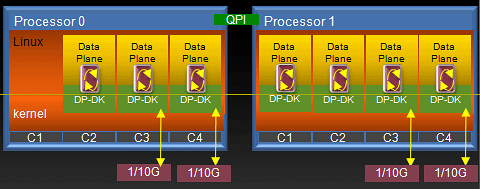
图4:Intel® DPDK 运行在Linux User Space模式下
如需在aTCA-6200A处理器刀片中建立Intel® DPDK,请在该内核中设置如下参数。
- GLIBC >=2.7
启用HPET和HPET MMAP配置选项
| # grep HPET /boot/config-`uname -r` CONFIG_HPET_TIMER=y CONFIG_HPET_EMULATE_RTC=y CONFIG_HPET=y CONFIG_HPET_MMAP=y |
- HUGETLBFS enabled:
| # mkdir /mnt/huge # mount -t hugetlbfs nodev /mnt/huge # echo 1024 > /sys/kernel/mm/hugepages/hugepages-\ 2048kB/nr_hugepages |
- 内核驱动程序加载(UIO):
| # sudo /sbin/modprobe uio # needed if uio is built as a module # sudo insmod <$RTE_HOME>/x86_64-default-linuxapp-\ gcc/kmod/igb_uio.ko |
在执行Intel® DPDK目标环境后,IP转发应用就能够作为Linux用户空间(User Space)的应用被运行。详细请参考Intel® Data Plane Development Kit - Getting Started Guide for Linux。
| # ./build/l3fwd -c 0x1 -- -p=0xF --config="(0,0,0)" Notes:
|
结果
在原生 Linux(Native Linux)和Intel® DPDK两种不同的环境下测试了aTCA-6200A刀片之后,我们比较了4个1GbE端口(2个来自前面板,2个来自Base接口)和2个10GbE Fabric端口在这两种不同配置下的IP转发性能。除此之外,我们还测试了当同时使用aTCA-6200A 6个网络端口(4个1GbE和2个10GbE)时,aTCA-6200A的合并IPv4转发性能。
使用4个1GbE端口时的性能比较
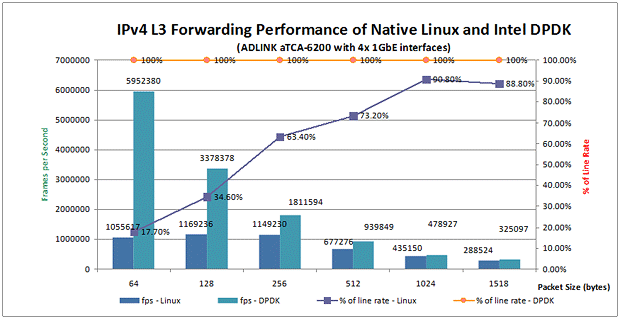
图5:使用4x 1GbE时IP转发能比较
原生 Linux(Native Linux)启用IP转发功能,并在aTCA-6200A的4个1GbE接口上运行IPv4转发, 64字节大小的帧可以以每秒100万个的速度被转发。当帧大小增加到1024字节时,原生 Linux(Native Linux)的IP转发可以达到100%的线率。但是在实际环境中,帧大小通常小于1024字节,因此100%的线率是无法实现的。但是,在同样的Linux操作系统下使用Intel® DPDK并运行在仅有的两个CPU线程上,aTCA-6200A能够以100%的线率转发帧数据,并且无论帧大小如何设置,都没有任何的丢帧现象发生,如上面图5所示。
相比Native Linux的IP转发性能,使用了Intel® DPDK之后的aTCA-6200A可以将转发性能提升6倍。
使用2个10GbE接口时的性能比较
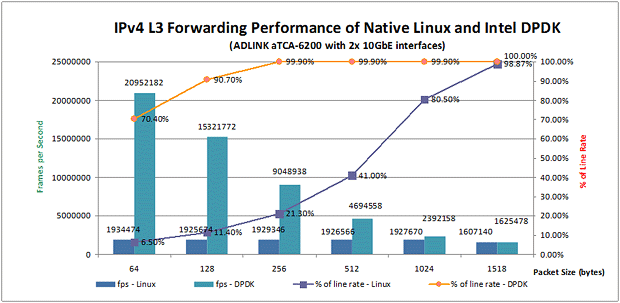
图6:使用2x 10GbE时IP转发能比较
在2个10GbE Fabric接口上进行IP转发测试时,无论是在原生 Linux(Native Linux)下还是基于Intel® DPDK,IP的转发性能相比使用4个1GbE接口时都有很大的提升。如上图6所示,相比原生 Linux(Native Linux)使用所有的CPU线程,采用了Intel® DPDK的aTCA-6200A只需要两个线程就可以获得10倍性能的提升。
aTCA-6200A全部的IPv4转发性能
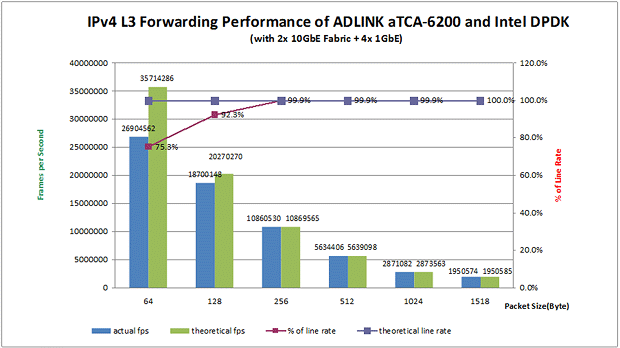
图7: 使用2x 10GbE + 4x 1GbE时IP转发能比较
使用aTCA-6200A全部的接口(2个10GbE Fabric接口,2个1GbE前置面板接口和2个1GbE Base接口)测试合并的IP转发性能时,使用Intel® DPDK后的aTCA-6200A每秒可以传输2700万个64字节的数据帧。换言之,理论上24Gbps的数据吞吐量有18Gbps可以被转发(即75.3%的线率)。此外,当数据帧分别为128字节和256字节时,吞吐量的线率可以提升到92.3%,甚至高达99%。
换言之,理论上24 Gbps的吞吐量高达18 Gbps的可转发(即线率 75.3%)。此外,即线率的吞吐量提高到92.3%,甚至高达99%,当帧的大小分别设置为128字节,256字节。
分析
相比原生 Linux(Native Linux),采用Intel® DPDK技术后能够大幅提升IP转性能的主要原因在于Intel® DPDK采用了如下描述的主要特征。
轮询模式取代中断
通常当数据包进入的时候,Native Linux会从网络接口控制器(NIC,Network Interface Controller)接收到中断,然后调度软中断,对所得的中断进行上下文切换,并唤醒系统调用,如read()和write()。
相比之下,Intel® DPDK采用了优化的轮询模式驱动(PMD,Poll Mode Driver)代替默认的以太网驱动程序,从而可以不断地接收数据包,避免软件中断,上下文切换和唤醒系统调用,从而大大的节省重要的CPU资源,并且降低了延迟。
HugePage取代传统页
相比Native Linux的4kB 页,采用更大的页尺寸意味着可以节省页的查询时间,并减少转译查找缓存(TLB,Translation Lookaside Buffer)丢失的可能。
Intel® DPDK作为用户空间(User-space)应用运行时,在自己的内存空间中分配HugePage至存储帧缓冲区,环形和其他相关缓冲区,这些缓冲区是由其他应用程序控制,甚至是Linux内核。本白皮书描述的测试中,总计1024@2MB的HugePage被保留用于运行IP转发应用。
零拷贝缓冲区
在传统的数据包处理过程中,原生 Linux(Native Linux)解封包的报头,然后根据Socket ID将数据复制到用户空间(User Space)缓冲区。一旦用户空间(User Space)应用程序完成了数据的处理,一个write()系统调用将被唤醒并把数据送至内核,负责将数据从用户空间(User Space)拷贝至内核缓冲区,封装包的报头,最后借助相关的物理端口将数据发出去。显然,原生 Linux(Native Linux)在内核缓冲区和用户空间(User Space)缓冲区之间进行拷贝动作,牺牲了很多的时间和资源。
相比之下,Intel® DPDK在自己保留的内存区域接收数据包,这个区域位于用户空间(User Space)缓冲区,之后根据配置规则将这些数据包分类到每一个Flow中。在处理完解封包之后,在相同的用户空间(User Space)缓冲区中使用正确的报头进行包封装,最后通过相关的物理端口发送这些数据。
Run-to-Completion(RTC,运行到完成)和Core Affinity
在执行应用之前,Intel® DPDK会进行初始化,分配所有的低级资源,如内存空间,PCI设备,定时器,控制台,这些资源将被保留且仅用于那些基于Intel® DPDK的应用。初始化完成之后,每一个核(或线程,当BIOS设置中启用了Intel®超线程技术时)将被启用来负责每一个执行单元,并根据实际应用的需求,运行相同的或不同的工作负载。
此外,Intel® DPDK还提供了一种方法,即可以设置每个执行单元运行在每一个核心上,以维持更多的Core Affinity,从而避免缓存丢失。在此白皮书描述的测试中,aTCA-6200A处理器刀片的物理端口根据Affinity被绑定在两个不同的CPU线程上。
无锁执行和缓存校准
Intel® DPDK提供的库和API,被优化成无锁,以防止多线程应用程序死锁现象的发生。对于缓冲区、环形和其他数据结构,Intel® DPDK也进行了优化,执行了缓存校准,以达到缓存行(Cache-Line)的效率最大化,同时最大限度减少缓存行(Cache-Line)的冲突。
结论
通过对在凌华科技aTCA-6200A的4个1GbE和2个10GbE Fabric端口使用和不使用Intel® DPDK(图5和图6)的测试结果进行分析,我们可以得出结论,在相同的硬件平台下,使用Intel® DPDK后的Linux仅用两个CPU线程进行IP转发的性能,与原生 Linux(Native Linux)使用全部的CPU线程进行IP转发的性能相比,前者是后者的10倍。
从图7中我们可以很容易的了解到,aTCA-6200A采用Intel® DPDK技术后的IPv4转发性能,可以让用户在迁移包处理应用时(从基于NPU的硬件迁移到基于Intel® x86的平台上),获得更好的成本和性能优势。同时可以采用统一的平台部署不同的服务,如应用处理,控制处理和包处理服务。
但是,值得注意的是,Intel® DPDK是一个数据层的开发工具包,并在用户空间运行,它不是一个用户可以直接建立应用程序的完整产品。需要特别指出的是,Intel® DPDK不包含需要与控制层(包括内核和协议堆栈)进行交互的工具。
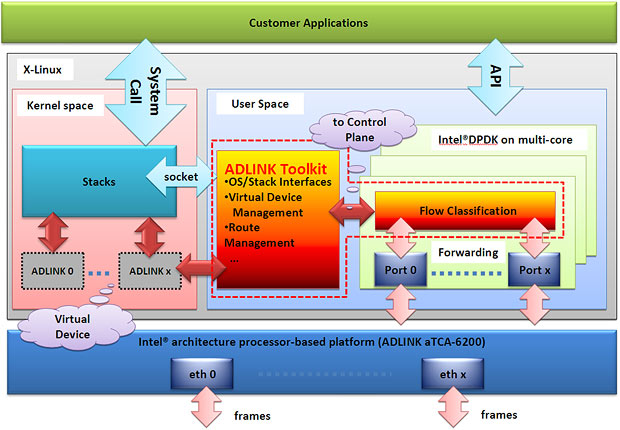
图8:凌华科技开发工具包与控制层和数据层协同工作的原理图
如图8所示,凌华科技已经开发出基于Intel® DPDK的开发工具包,用以管理控制层和数据层,如同控制层的克隆虚拟网卡一样执行任务,可以在数据层同步物理端口。使用该开发工具包,用户可以轻松地开发基于Intel® DPDK的应用,并与控制层和数据层进行交互,不仅可以有效提升包处理性能,还能让开发更简单,缩短产品上市时间。
附件下载:
 公安机关备案号:13010302000361
公安机关备案号:13010302000361